What happens when you train a model to detect hate speech in Hindi, and then ask it to find hate speech in Marathi with zero or minimal examples?
For my Neural Networks and Deep Learning class at Columbia, my team and I ran a controlled empirical study to figure this out. We pitted two major Indic-focused encoders against each other to see how different pretraining strategies affect cross-lingual transfer.
The Contenders & The Stack
Experiment Setup
- > Model A: IndicBERT-v2 (Brute force: massive monolingual corpora)
- > Model B: MuRIL (Alignment focus: Translation Language Modeling)
- > Stack: PyTorch, HuggingFace Transformers, PEFT
- > Technique: Low-Rank Adaptation (LoRA)
The Regularization Effect of LoRA
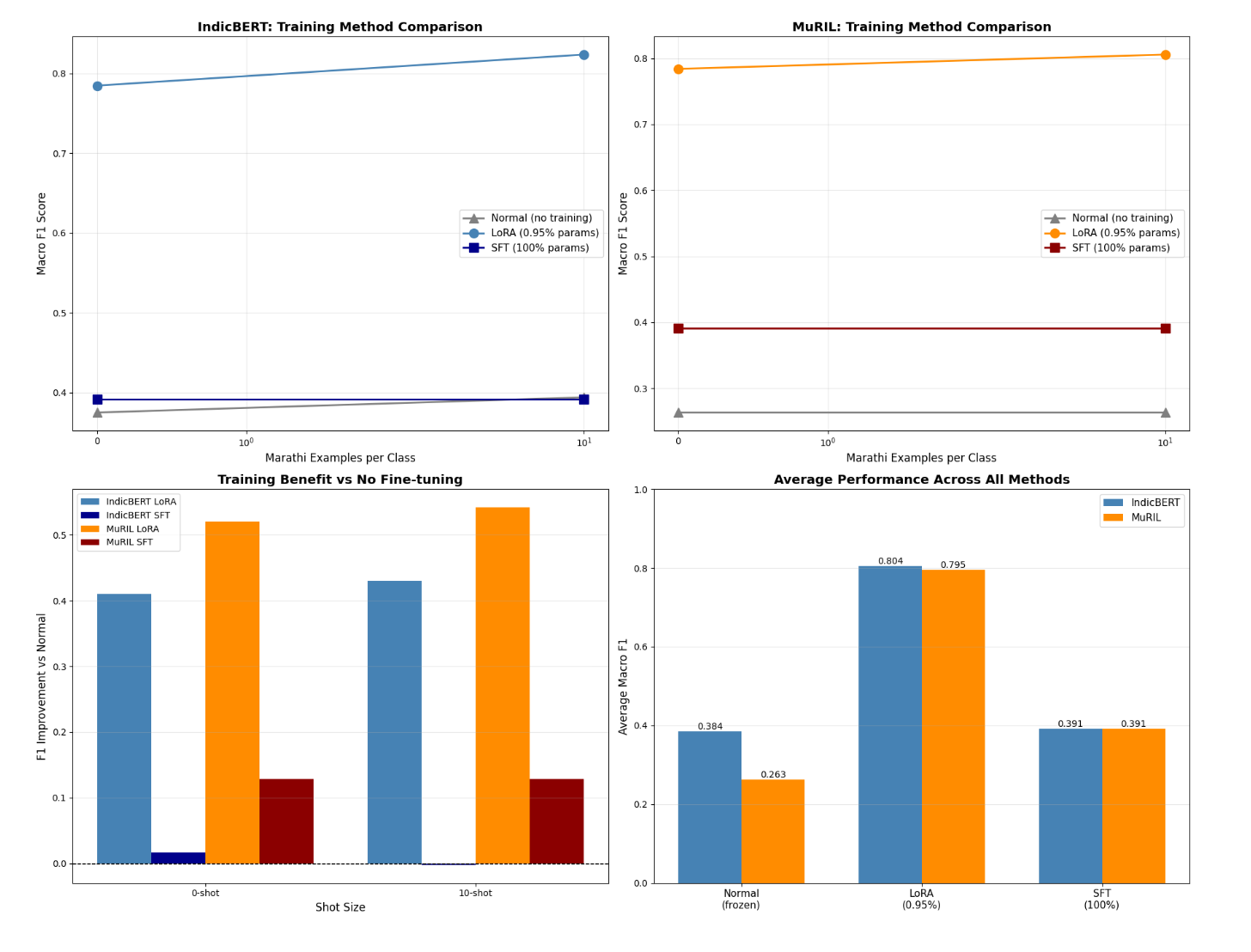
The most interesting takeaway was not just the final F1 score; it was how the models got there. When we attempted full fine-tuning on the limited dataset, the models catastrophically failed. They collapsed entirely into majority-class predictions (F1 ~0.39).
But when we applied LoRA, we hit an F1 of ~0.80 while updating less than 1% of the model parameters. In highly low-resource settings, parameter-efficient fine-tuning is not just a computational shortcut-it acts as a structural regularizer that helps prevent catastrophic forgetting and keeps training stable.
Corpus Scale vs. Explicit Alignment
So, which pretraining strategy won? It depends on the context window.
IndicBERT-v2 dominated zero-shot transfer. Because it was trained on a massive corpus (IndicCorp v2), it had strong language-agnostic representations out of the box.
MuRIL, however, won the few-shot battle. Because it was explicitly trained to align translations across languages, it showed stronger plasticity. Given just 50 target-language Marathi examples, it adapted quickly and outperformed IndicBERT by 2.1% F1.